Abstract
We propose MASSTAR, a multi-modal large-scale scene dataset with a versatile toolchain for surface prediction and completion.
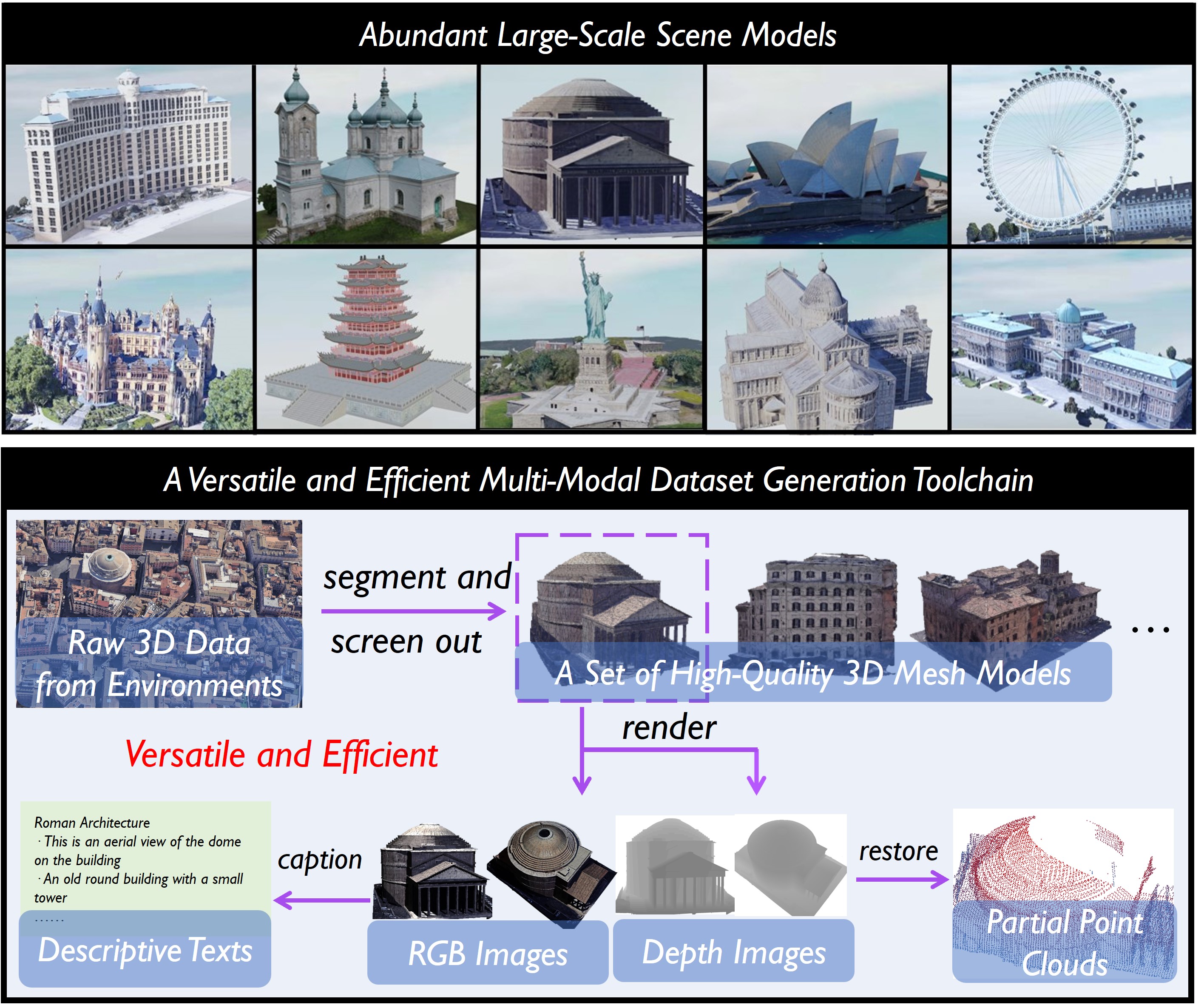
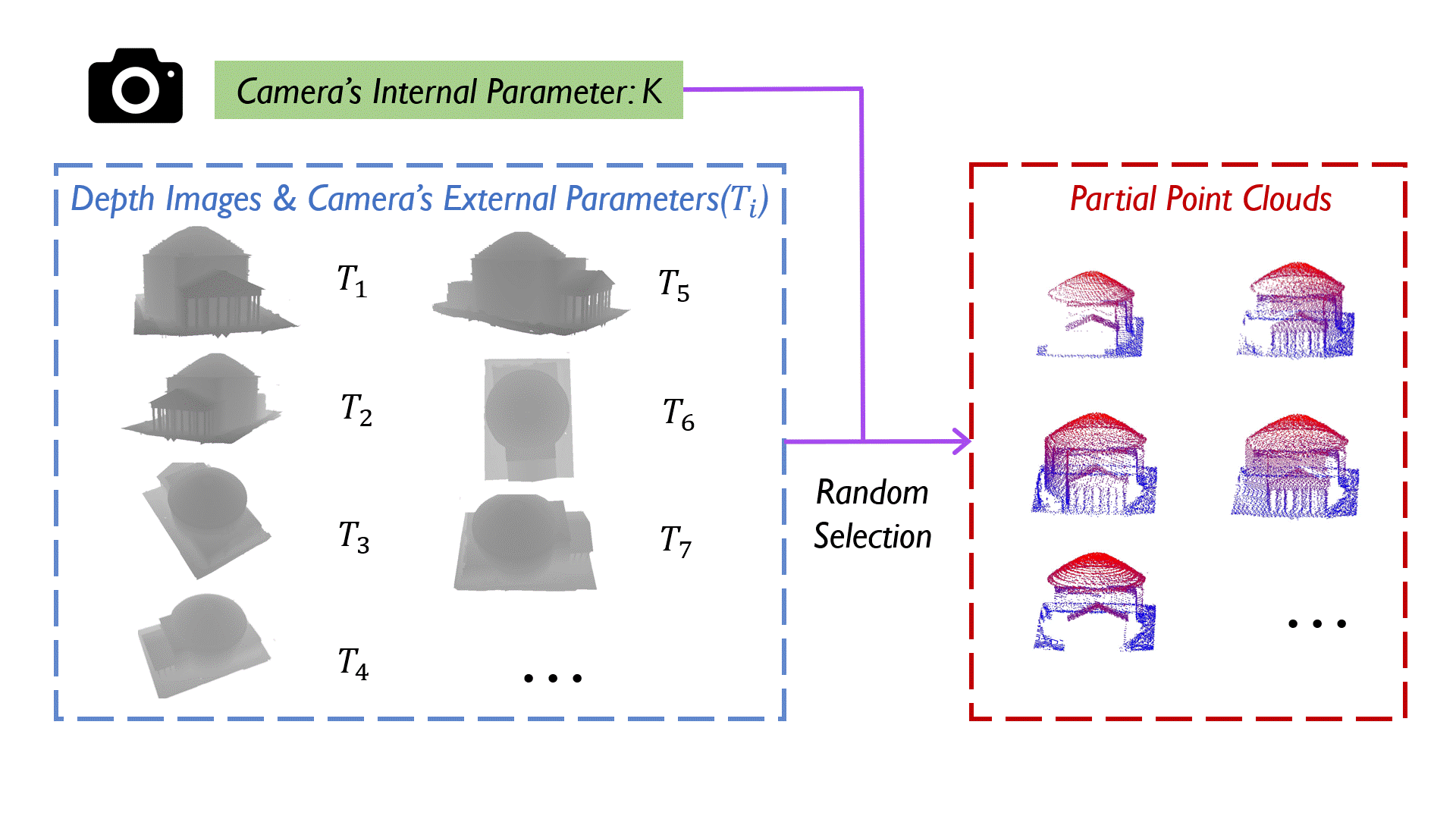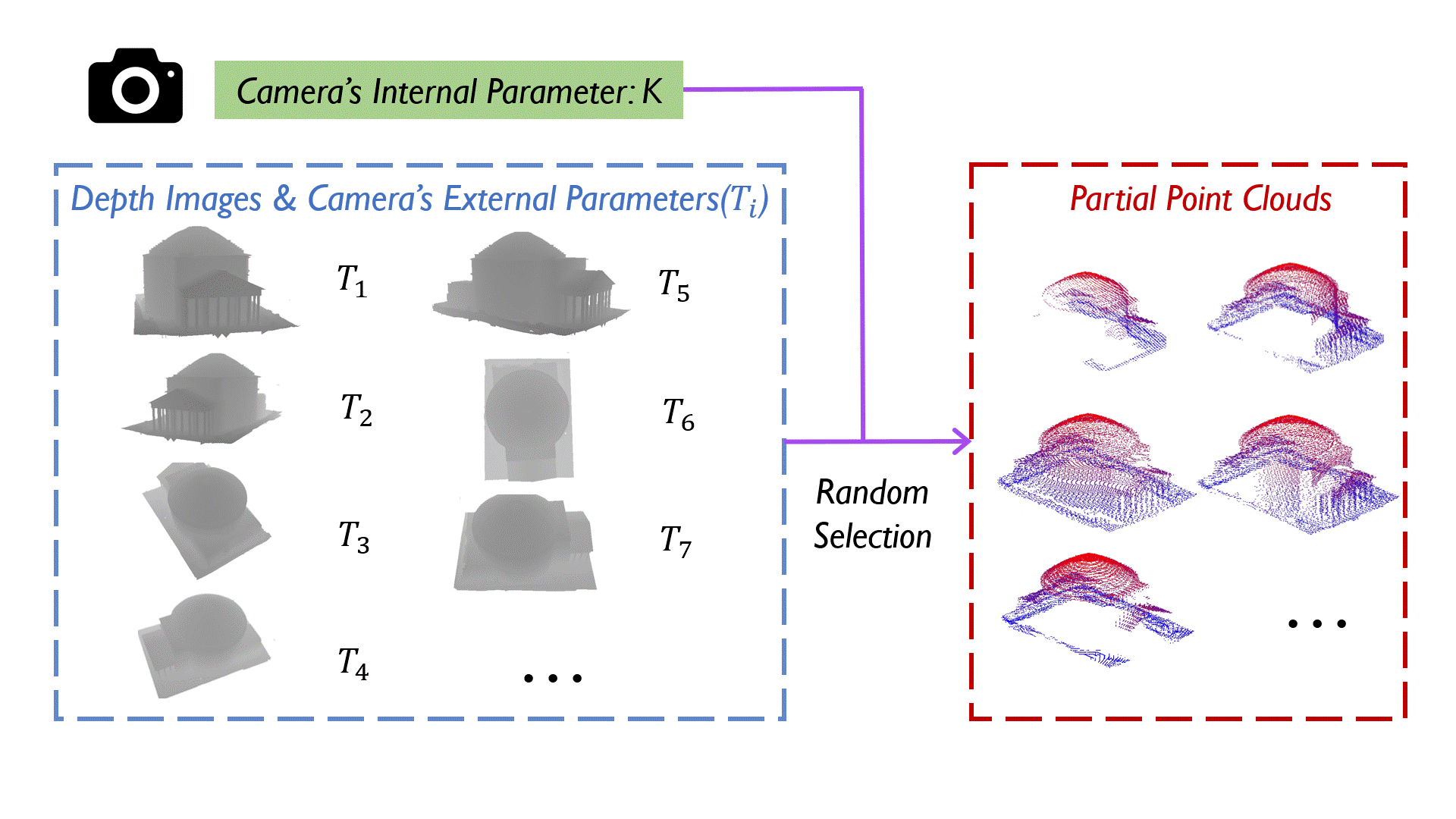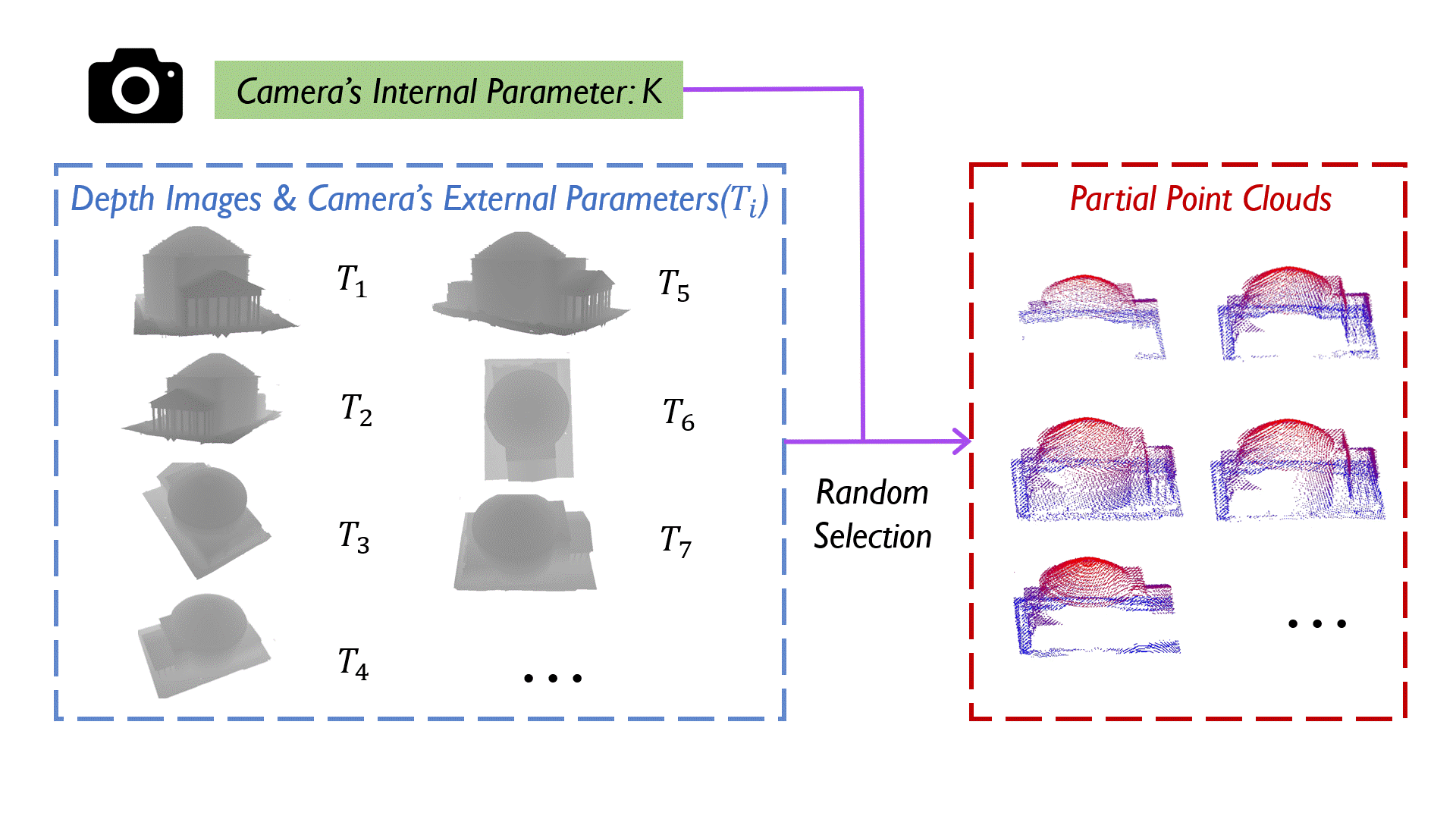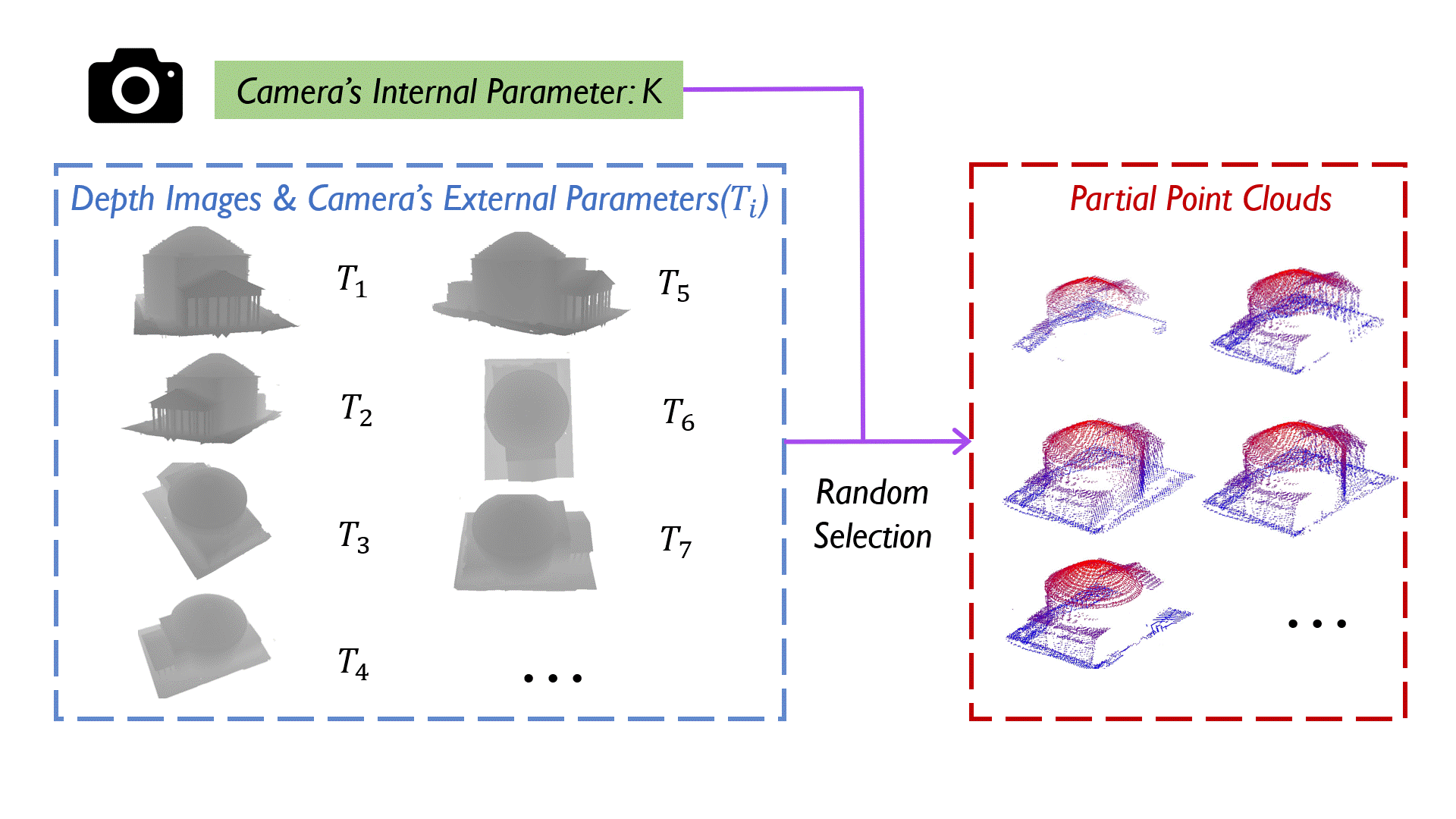
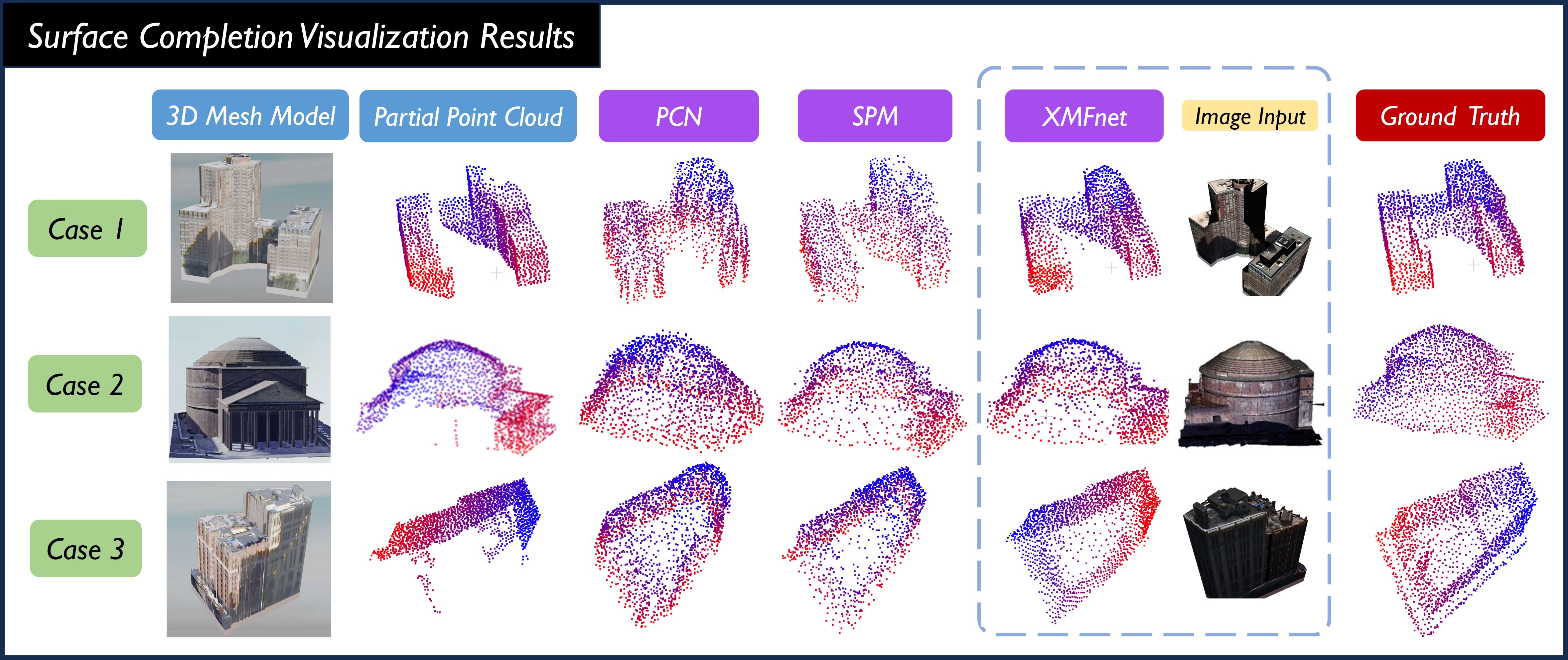
Surface prediction and completion have been widely studied in various applications. Recently, research in surface completion has evolved from small objects to complex large-scale scenes. As a result, researchers have begun increasing the volume of data and leveraging a greater variety of data modalities including rendered RGB images, descriptive text, depth images, etc, to enhance algorithm performance. However, existing datasets suffer from a deficiency in the amounts of scene-level models along with the corresponding multi-modal information. Therefore, a method to scale the datasets and generate multi-modal information in them efficiently is essential. To bridge this research gap, we propose MASSTAR: a multi-modal large-scale scene dataset with a versatile toolchain for surface prediction and completion. We develop a versatile and efficient toolchain for processing the raw 3D data from the environments. It screens out a set of fine-grained scene models and generates the corresponding multi-modal data. Utilizing the toolchain, we then generate an example dataset composed of over a thousand scene-level models with partial real-world data added. We compare MASSTAR with the existing datasets, which validates its superiority: the ability to efficiently extract high-quality models from complex scenarios to expand the dataset. Additionally, several representative surface completion algorithms are benchmarked on MASSTAR, which reveals that existing algorithms can hardly deal with scene-level completion.